Per chi viene dal mondo Windows uno degli elementi di spicco e potenzialmente di confusione di Linux è che non esiste “la” distribuzione Linux ufficiale, intesa come combinazione sia del sistema operativo in sé sia dell’ambiente di interfaccia.
Lo stesso problema si presenta per chi cerca una distribuzione Linux per l’installazione su un server aziendale. Ecco alcune possibilità, considerate solo tra le “distro” che sono adatte, se non proprio predisposte in modo specifico, per i server.
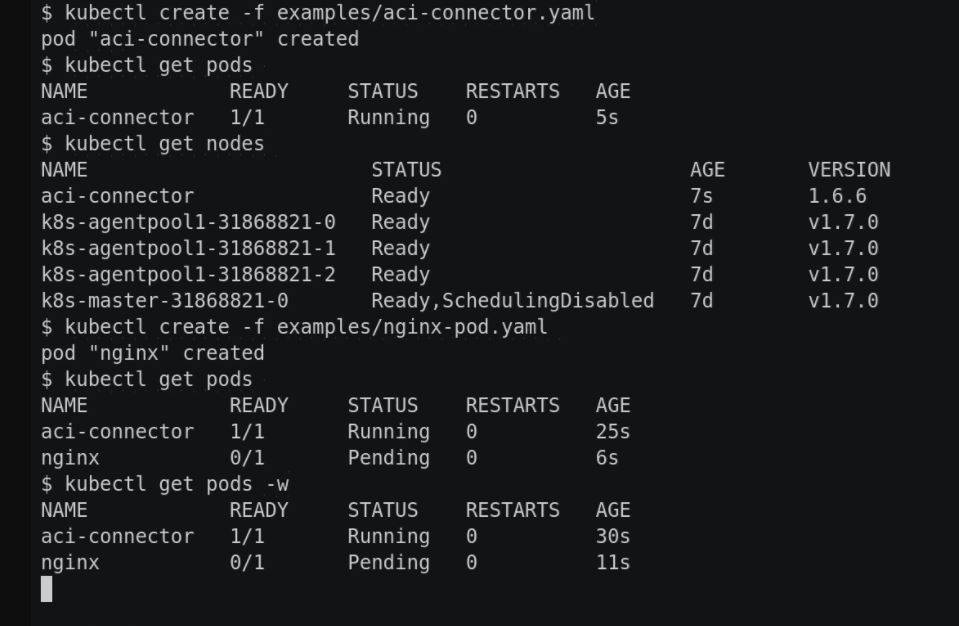
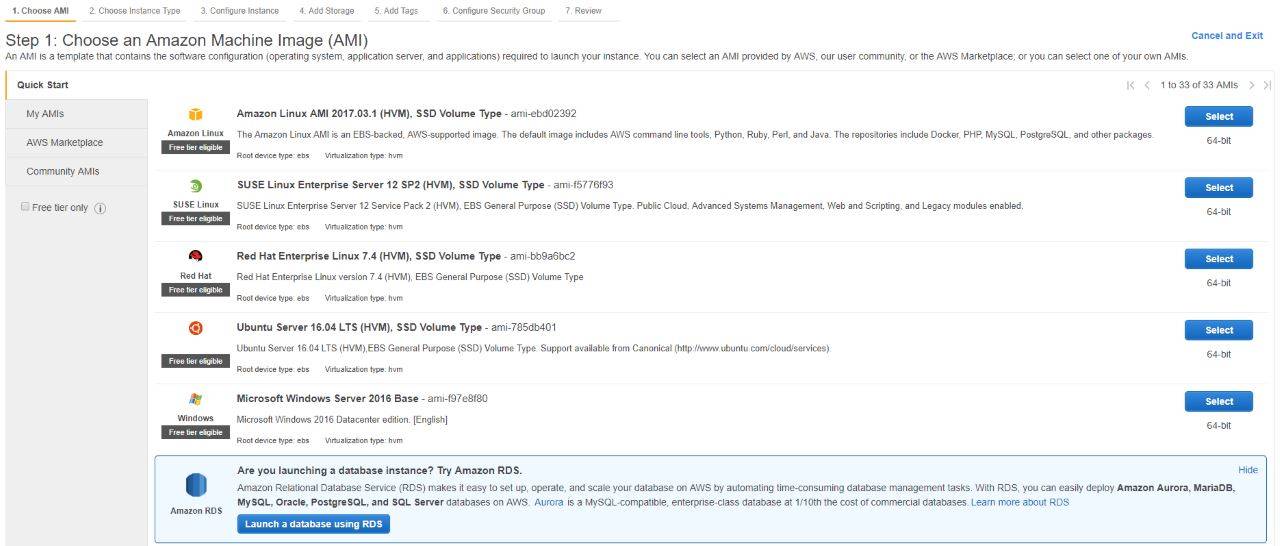
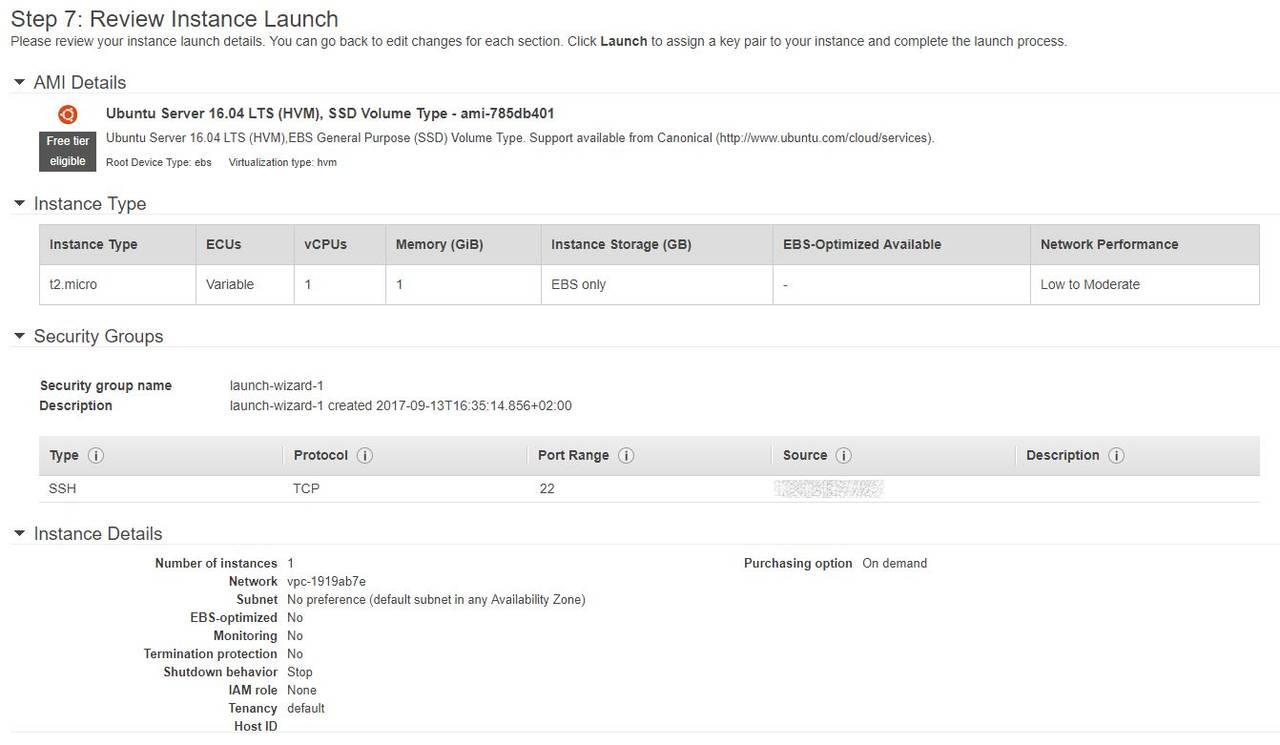
Ubuntu 16.04 LTS
Ubuntu è una delle distribuzioni Linux più diffuse in ambito client, ma ha anche una versione LTS (sta per Long Term Support) indicata per l’installazione in azienda come sistema operativo server.
Non si tratta della versione effettivamente Server ma è particolarmente indicata perché – come lascia capire la denominazione – si tratta di una release garantita come stabile e supportata a lungo termine (per cinque anni). Questo dovrebbe essere una garanzia adeguata per chi voglia usare la piattaforma per erogare servizi anche business-critical.
Ubuntu tra l’altro è un sistema operativo gestibile senza problemi anche in cloud, dato che ci sono immagini certificate per tutti i principali cloud provider tra cui AWS, Google e Microsoft. Il supporto a OpenStack permette comunque di realizzare, se si hanno le giuste competenze, un ambiente cloud proprio.
Il sistema comprende una serie di tool di management molto completa, tanto che è possibile gestire un gran numero di istanze server da una singola console.
Oracle Linux 7.3
Oracle Linux deriva da Red Hat Enterprise Linux. Il punto di partenza è quindi una distribuzione allo stesso tempo completa e stabile, a cui Oracle aggiunge alcuni potenziamenti interessanti. Il principale è lo Unbreakable Enterprise Kernel, che amplia le funzioni e la robustezza del sistema operativo per aspetti specifici come le prestazioni nella gestione delle transazioni, la sicurezza e la virtualizzazione.
La conseguenza è che Oracle Linux diventa, ovviamente non a caso, il complemento ideale di altre piattaforme Oracle, in primis i database ma anche le applicazioni di business. L’integrazione tra questi componenti e il kernel del sistema operativo è infatti superiore a quella possibile con altre distribuzioni più generaliste.
Va anche tenuto conto del fatto che il sistema operativo comprende una propria piattaforma di virtualizzazione, il che permette di creare ambienti IT anche articolati.
Red Hat Enterprise Linux 7.4
RHEL è un po’ la distribuzione Linux aziendale per antonomasia. Si tratta di un sistema operativo server molto solido, aperto a tutto lo stack di componenti open source che Red Hat ha sviluppato e continua a portare avanti. A questo si aggiungono opzioni di supporto molto complete. L’altro lato della medaglia è che tutto ciò ha un prezzo, crescente man mano che dal sistema operativo di base si passa a configurazioni più complesse.
Il fattore costo può essere un elemento importante oppure no, dipende da cosa si intende fare con la piattaforma e da quali sono in generale i propri requisiti di business. Si tratta nel complesso di una piattaforma enterprise adatta alle aziende che non vogliono rischi ma anzi la possibilità di essere supportate in ogni momento, sia da Red Hat sia da una rete di partner e integratori molto vasta.
Fedora 26 Server
Fedora è un progetto collegato a Red Hat e sussiste quindi una parentela abbastanza stretta fra la distribuzione principale e questa. La differenza fondamentale è che laddove RHEL punta alla massima stabilità, Fedora punta a incorporare prima possibile le innovazioni sviluppate in ambito Linux. Per questo ne viene rilasciata una versione nuova ogni sei mesi.
Non si tratta quindi della “distro” ideale per chi intende usare Linux come base per applicazioni e servizi business critical. In scenari come questi l’aggiornamento del sistema operativo ogni sei mesi potrebbe essere troppo oneroso, anche perché il supporto può venire più che altro dalla comunità online. Certo la novità ha il suo fascino, che però va valutato caso per caso.
SUSE Linux Enterprise Server 12 SP3
Il grande punto di forza di questa distribuzione è l’adattabilità. La distribuzione di base è molto leggera: se la si usa così com’è, è un buon punto di partenza per implementazioni molto semplici o come piattaforma host per applicazioni di virtualizzazione. Ma è anche la base per realizzare vere e proprie “distribuzioni” – meglio sarebbe dire installazioni – personalizzate.
Per chi invece vuole salire in complessità questa distribuzione è molto articolata e su alcune piattaforme può scalre sino a migliaia di CPU logiche. Comprende il supporto a diversi filesystem e oltre 2.500 package mirati. La buona variabilità della piattaforma si riflette anche in una variabilità nei costi. La versione base – il sistema operativo in sé – è gratuita, i costi sono legati ai vari piani di supporto possibili, che variano per durata, livello di assistenza e tipo di implementazione (on-premise, cloud, virtualizzata).





































 Mai come in questa lineup il display è un elemento di caratterizzazione importante. Da un lato c’è il display top di Apple – quello di iPhone X – e dall’altro tutto il resto, che conosciamo bene e che già sappiamo cosa è in grado di offrirci.
Mai come in questa lineup il display è un elemento di caratterizzazione importante. Da un lato c’è il display top di Apple – quello di iPhone X – e dall’altro tutto il resto, che conosciamo bene e che già sappiamo cosa è in grado di offrirci. Tra iPhone 6s/SE e 8/X ci sono tre generazioni di processori Apple con caratteristiche ben diverse. La CPU A9 di iPhone SE e 6s è di concezione tradizionale, mentre con il processore A10 Fusion di iPhone 7 ha debuttato la gestione dinamica dei core interni a seconda del carico di lavoro, concetto portato più avanti dalla CPU
Tra iPhone 6s/SE e 8/X ci sono tre generazioni di processori Apple con caratteristiche ben diverse. La CPU A9 di iPhone SE e 6s è di concezione tradizionale, mentre con il processore A10 Fusion di iPhone 7 ha debuttato la gestione dinamica dei core interni a seconda del carico di lavoro, concetto portato più avanti dalla CPU  iPhone X e 8 non hanno cambiato le regole del gioco: la versione “fotografica” degli smartphone Apple resta quella con la doppia ottica posteriore, quindi le versioni 8 Plus oppure iPhone X. In queste avere un processore particolarmente potente nella parte grafica (A11) ha permesso di introdurre la funzione Portrait Lighting per realizzare ritratti creativi. Anche se la funzione è ufficialmente in versione beta, come è stato a lungo per il Portrait Mode di iPhone 7 Plus (a cui resta il terzo gradino di un ipotetico podio fotografico).
iPhone X e 8 non hanno cambiato le regole del gioco: la versione “fotografica” degli smartphone Apple resta quella con la doppia ottica posteriore, quindi le versioni 8 Plus oppure iPhone X. In queste avere un processore particolarmente potente nella parte grafica (A11) ha permesso di introdurre la funzione Portrait Lighting per realizzare ritratti creativi. Anche se la funzione è ufficialmente in versione beta, come è stato a lungo per il Portrait Mode di iPhone 7 Plus (a cui resta il terzo gradino di un ipotetico podio fotografico). Qui entrano in gioco essenzialmente Face ID per iPhone X e la ricarica wireless per anche iPhone 8. Sono due elementi distintivi, ma abbastanza da influenzare decisamente una scelta di acquisto? Probabilmente no.
Qui entrano in gioco essenzialmente Face ID per iPhone X e la ricarica wireless per anche iPhone 8. Sono due elementi distintivi, ma abbastanza da influenzare decisamente una scelta di acquisto? Probabilmente no. Difficile consigliare un modello piuttosto che un altro senza mettere in campo il fattore costo. Sarebbe scontato dire che iPhone X sia il più interessante, si porta però dietro un cartellino del prezzo da quasi 1.200 euro che qualche domanda la fa porre a chiunque. Il contenuto tecnologico-innovativo è indubbio e la qualità costruttiva anche, diciamo però che Tim Cook è probabilmente molto ottimista nel considerare quello di iPhone X un “value price”.
Difficile consigliare un modello piuttosto che un altro senza mettere in campo il fattore costo. Sarebbe scontato dire che iPhone X sia il più interessante, si porta però dietro un cartellino del prezzo da quasi 1.200 euro che qualche domanda la fa porre a chiunque. Il contenuto tecnologico-innovativo è indubbio e la qualità costruttiva anche, diciamo però che Tim Cook è probabilmente molto ottimista nel considerare quello di iPhone X un “value price”.

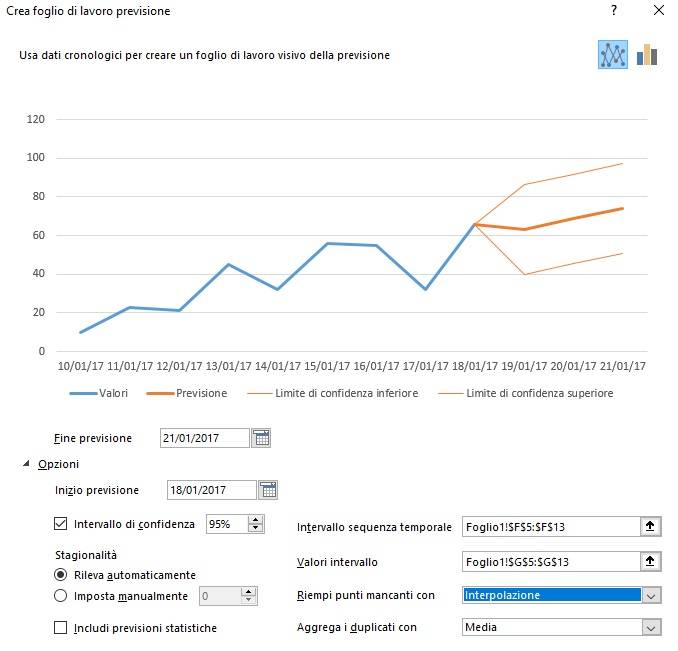




















 Il sistema si basa sulla gestione dei cookie, in particolare sulla possibilità che un sito web ha di consultare i cookie creati da un altro. Come i siti possono condividere contenuti generici, possono in teoria condividere anche i cookie. In questo modo ad esempio il sito di un quotidiano “vede” che abbiamo visitato in precedenza il sito del produttore A e in particolare abbiamo consultato informazioni sul prodotto B, quindi può presentare pubblicità online mirata su quel prodotto. Anche semplicemente le offerte di Amazon, per dire.
Il sistema si basa sulla gestione dei cookie, in particolare sulla possibilità che un sito web ha di consultare i cookie creati da un altro. Come i siti possono condividere contenuti generici, possono in teoria condividere anche i cookie. In questo modo ad esempio il sito di un quotidiano “vede” che abbiamo visitato in precedenza il sito del produttore A e in particolare abbiamo consultato informazioni sul prodotto B, quindi può presentare pubblicità online mirata su quel prodotto. Anche semplicemente le offerte di Amazon, per dire.
 È anche una utility molto essenziale. Tecnicamente è un demone che si mantiene in esecuzione e rileva la pressione di Invio e Delete. Se il Finder è attivo e un file è selezionato, a quel punto Invio lo apre (invece di modificarne il nome) e Delete lo sposta nel Cestino. PresButan associa la cancellazione anche al tasto Cancella, per chi ha una tastiera estesa.
È anche una utility molto essenziale. Tecnicamente è un demone che si mantiene in esecuzione e rileva la pressione di Invio e Delete. Se il Finder è attivo e un file è selezionato, a quel punto Invio lo apre (invece di modificarne il nome) e Delete lo sposta nel Cestino. PresButan associa la cancellazione anche al tasto Cancella, per chi ha una tastiera estesa. Dopo il lancio il demone resta attivo fino a quando non lo disattiviamo noi. Lo si fa con la combinazione di tasti Control-Comando-Cancella, ma sui Mac portatili bisogna premere anche il tasto Fn per via di come viene riconosciuto il tasto Delete in alto a destra. Se per qualche motivo la combinazione di tasti non viene riconosciuta si può solo disattivare il demone usando Monitoraggio Attività.
Dopo il lancio il demone resta attivo fino a quando non lo disattiviamo noi. Lo si fa con la combinazione di tasti Control-Comando-Cancella, ma sui Mac portatili bisogna premere anche il tasto Fn per via di come viene riconosciuto il tasto Delete in alto a destra. Se per qualche motivo la combinazione di tasti non viene riconosciuta si può solo disattivare il demone usando Monitoraggio Attività.